Verified by VISA under lupp
Det här har jag längtat efter. Gubbarna från Cambridge har kikat på 3-D Secure, mer känt som Verified by VISA eller MasterCard SecureCode. Det ser inte bra ut.
Verified by VISA och MasterCard SecureCode är egentligen samma sak. Det är när du får sätta ett lösenord för ditt kort på internetbanken, ett lösenord som sedan måste anges innan ett köp slutförs i en webbshop. Det kommer att bli vanligare och vanligare framöver att handlare gör den här kollen, det minskar nämligen deras risk eftersom bankerna tar på sig smällen vid eventuella bedrägerier. De har alltså incitament att öka sin säkerhet.
I rapporten Verified by Visa and MasterCard SecureCode: or, How Not to Design Authentication (pdf) diskuterar de ett antal svagheter i systemet. Framförallt handlar det om att systemet uppmuntrar användare till ett riskbeteende. Viktigt att veta är dock att säkerheten i viss grad beror på hur banker implementerar det så YMMV när du jämför din egen bank med rapporten.
Så vad rekommenderar Steven J. Murdoch och Ross Anderson att trion (banker, handlare och betalningsnätverken) ska göra åt saken egentligen?
What should be done techincally? We believe that single sign-on is the wrong model. What's needed is transaction authentication. The system should ask the customer, "You're about to pay $X to merchant Y. If this is OK, enter the auth code". This could be added to 3DS using SMS messaging, or systems like Cronto or CAP (Chip Authentication Program) as a stopgap. In the long term we need to move to a trustworthy payment device.
Luttrade läsare känner förstås igen det här, senast från Gartner-rapporten förra veckan.
--
Stefan Pettersson
Verified by VISA och MasterCard SecureCode är egentligen samma sak. Det är när du får sätta ett lösenord för ditt kort på internetbanken, ett lösenord som sedan måste anges innan ett köp slutförs i en webbshop. Det kommer att bli vanligare och vanligare framöver att handlare gör den här kollen, det minskar nämligen deras risk eftersom bankerna tar på sig smällen vid eventuella bedrägerier. De har alltså incitament att öka sin säkerhet.

I rapporten Verified by Visa and MasterCard SecureCode: or, How Not to Design Authentication (pdf) diskuterar de ett antal svagheter i systemet. Framförallt handlar det om att systemet uppmuntrar användare till ett riskbeteende. Viktigt att veta är dock att säkerheten i viss grad beror på hur banker implementerar det så YMMV när du jämför din egen bank med rapporten.
Så vad rekommenderar Steven J. Murdoch och Ross Anderson att trion (banker, handlare och betalningsnätverken) ska göra åt saken egentligen?
What should be done techincally? We believe that single sign-on is the wrong model. What's needed is transaction authentication. The system should ask the customer, "You're about to pay $X to merchant Y. If this is OK, enter the auth code". This could be added to 3DS using SMS messaging, or systems like Cronto or CAP (Chip Authentication Program) as a stopgap. In the long term we need to move to a trustworthy payment device.
Luttrade läsare känner förstås igen det här, senast från Gartner-rapporten förra veckan.
--
Stefan Pettersson
Allt du vill veta om CAPTCHA
Du har säkert sett sådana här när du har registrerat ett konto på någon webbsida:
Programmen som hanterar dessa bilder kallas CAPTCHA och som du säkert misstänkt så finns de där som en säkerhetsfunktion. Vad skyddar de mot och hur bra fungerar de?
Bakgrund
CAPTCHA står för Completely Automated Public Turing test to tell Computers and Humans Apart. Det handlar alltså om att kunna skilja på människor och datorer, eller egentligen, om möjligheten för en människa att bevisa att hon inte är en dator.
Behovet finns eftersom Internet har många resurser som kan missbrukas genom automatisering. En angripare skulle t ex kunna skriva ett program som under några timmar registrerar 20 000 mailkonton på Spray och sedan skickar ett tiotal mail var; ett enkelt och relativt oskyldigt sätt att slussa ut en kvarts miljon spammail. Ett annat klassiskt exempel är en omröstning som hölls på Slashdot 1999 om vilken skola som hade den bästa utbildningen i datavetenskap. Efter att studenter på Carnegie Mellon hade skrivit ett program för att rösta automatiskt ryckte snart studenter från MIT in och det urartade i en tävling om vem som skrev det mest effektiva röstprogrammet. Carnegie och MIT fick strax över 20 000 röster var medan trean fick knappt 1000.
Den formella definitionen är att en CAPTCHA är ett program som kan generera och bedöma tester som (1) de flesta människor kan klara av men (2) dagens datorer inte klarar. Det populäraste testet har visat sig vara att kunna läsa deformerad text, något som datorer generellt har svårt för medan människor är väldigt duktiga på. Definitionen på en CAPTCHA lämnar dock testets typ öppet.
Däremot, om man följer direktiven för en CAPTCHA strängt så ska programmets beståndsdelar vara öppna (Public Turing test). Dels för att följa Kerckhoffs princip men också för att en välkommen bieffekt är att forskning runt artificell intelligens drar nytta av kapprustningen kring CAPTCHA-program. I den här texten använder jag alltså termen något oansvarigt.
Som vanligt inom säkerhet så är inte CAPTCHA en fullständig lösning på problemet. Implementeringar är fyllda av fällor.
Svagheter och attacker
Det första man behöver övertyga sig om är hur en lyckad attack ser ut. En CAPTCHA-knäckare behöver inte vara perfekt; en angripare kan t ex nöja sig med att, i genomsnitt, var tionde försök är korrekt. Detta leder direkt till att test med en väldigt begränsat mängd möjliga svar kan betraktas som svaga. Se till exempel metoden Spray använder för att kontrollera användare som glömt sitt lösenord.
Hos Spray är ett av ett litet antal (här fem stycken) möjliga svar rätt. En 20-procentig hit rate genom blint gissande är fullt godtagbart för en angripare. (Sprays implementering lider av flera problem men det lämnas som en övning för läsaren.)
En annan faktor än (lite slarvigt) lösningsrymden är (lite slarvigt) problemrymden. Hur många bilder har Spray i databasen? Är det möjligt att ladda ner alla och identifiera dem en gång och sedan utnyttja kunskapen för att lösa alla framtida? Om databasen innehåller 200 bilder är det något jag skulle kunna ägna några timmar åt. Om databasen innehåller 3,4 miljoner bilder är jag inte riktigt lika sugen.
Det här knyter an i text-CAPTCHA-metoden. Standardattacken är att använda OCR-program (Optical Character Recognition) för att tolka bilden som text. Om de textsträngar som testet använder är riktiga ord från t ex engelska så minskar antalet möjliga gissningar radikalt. Om OCR-programmet analyserar en bild, hittar en text och tolkar den som BRNANA men samtidigt meddelar att den är osäker på den andra bokstaven är det förstås ett enkelt steg att kontrollera med en ordlista innan gissning. Sannolikt kommer det att visa sig att BANANA har det kortaste avståndet till BRNANA.
Ytterligare en uppenbar svaghet är algoritmer som inte utnyttjar slumptal. Om de deformationer som används för att förvränga texten alltid är samma har angripare möjlighet att hitta andra deformationer som inverterar effekten. (Det här beror förstås på att data inte förloras vid vissa deformationer, något som somliga har fått lära sig den hårda vägen.)
En mindre uppenbar svaghet i text-CAPTCHA-bilder är när enskilda bokstäver är enkla att separera från varandra. Jämför t ex Googles nuvarande CAPTCHA med en av de tidigaste exemplen; EZ-Gimpy nedan. Om bokstäverna kan anlyseras var för sig förenklas attacker rejält.
Redan under CAPTCHAs barndom fruktade man att människor skulle utnyttjas för att lösa testerna. En farhåga man hade var att porrsidor skulle sättas upp där besökare fick lösa en CAPTCHA varje gång de ville se ett gäng bilder. De test som besökarna löste genererades inte av porrservern utan skulle då tas från Hotmails användarregistrering så att porrsurfare, ovetandes, registrerade mailkonton. De goda nyheterna är att det här aldrig blev ett riktigt problem, åtminstone inte vad man vet. De dåliga nyheterna är istället att CAPTCHA-knäckare rekryterades i låglöneländer. Det finns tyvärr inte så mycket information om hur utbredd metoden är.
Förutom detta finns det förstås flera exempel på program avsedda för att knäcka CAPTCHA-tester.
Andra problem
Det är inte det här inläggets fokus men det är viktigt att påpeka; CAPTCHA-tester må vara svåra för dagens datorer att lösa men de är också svåra för en ansenlig del människor. En arbetsgrupp på W3C släppte en rapport på ämnet för fem år sedan; Inaccessibility of CAPTCHA:
A common method of limiting access to services made available over the Web is visual verification of a bitmapped image. This presents a major problem to users who are blind, have low vision, or have a learning disability such as dyslexia. This document examines a number of potential solutions that allow systems to test for human users while preserving access by users with disabilities.
Rekommendationer
Precis som med kryptering så ska man inte göra som Martin Timell; själv. Lägg istället krut på en känd CAPTCHA. Jag rekommenderar vanligtvis reCAPTCHA (som är gratis). Huvudsaken är att eventuellt lyckade attacker hanteras relativt snabbt. Det hände till exempel med just reCAPTCHA i december. När en sådan utbredd CAPTCHA knäcks är det större chans att det upptäcks, rapporteras och hanteras.
Generellt är det ganska svårt att ge riktlinjer för hur en stark CAPTCHA ser ut. Olika deformationer och algoritmer kan tillsammans ha oförutsedda effekter. Eftersom konceptet CAPTCHA är fött på universitet finns det gott om utrymme för en akademisk syn...
Trots detta kan några riktlinjer vara:
--
Stefan Pettersson

Programmen som hanterar dessa bilder kallas CAPTCHA och som du säkert misstänkt så finns de där som en säkerhetsfunktion. Vad skyddar de mot och hur bra fungerar de?
Bakgrund
CAPTCHA står för Completely Automated Public Turing test to tell Computers and Humans Apart. Det handlar alltså om att kunna skilja på människor och datorer, eller egentligen, om möjligheten för en människa att bevisa att hon inte är en dator.
Behovet finns eftersom Internet har många resurser som kan missbrukas genom automatisering. En angripare skulle t ex kunna skriva ett program som under några timmar registrerar 20 000 mailkonton på Spray och sedan skickar ett tiotal mail var; ett enkelt och relativt oskyldigt sätt att slussa ut en kvarts miljon spammail. Ett annat klassiskt exempel är en omröstning som hölls på Slashdot 1999 om vilken skola som hade den bästa utbildningen i datavetenskap. Efter att studenter på Carnegie Mellon hade skrivit ett program för att rösta automatiskt ryckte snart studenter från MIT in och det urartade i en tävling om vem som skrev det mest effektiva röstprogrammet. Carnegie och MIT fick strax över 20 000 röster var medan trean fick knappt 1000.
Den formella definitionen är att en CAPTCHA är ett program som kan generera och bedöma tester som (1) de flesta människor kan klara av men (2) dagens datorer inte klarar. Det populäraste testet har visat sig vara att kunna läsa deformerad text, något som datorer generellt har svårt för medan människor är väldigt duktiga på. Definitionen på en CAPTCHA lämnar dock testets typ öppet.
Däremot, om man följer direktiven för en CAPTCHA strängt så ska programmets beståndsdelar vara öppna (Public Turing test). Dels för att följa Kerckhoffs princip men också för att en välkommen bieffekt är att forskning runt artificell intelligens drar nytta av kapprustningen kring CAPTCHA-program. I den här texten använder jag alltså termen något oansvarigt.
Som vanligt inom säkerhet så är inte CAPTCHA en fullständig lösning på problemet. Implementeringar är fyllda av fällor.
Svagheter och attacker
Det första man behöver övertyga sig om är hur en lyckad attack ser ut. En CAPTCHA-knäckare behöver inte vara perfekt; en angripare kan t ex nöja sig med att, i genomsnitt, var tionde försök är korrekt. Detta leder direkt till att test med en väldigt begränsat mängd möjliga svar kan betraktas som svaga. Se till exempel metoden Spray använder för att kontrollera användare som glömt sitt lösenord.

Hos Spray är ett av ett litet antal (här fem stycken) möjliga svar rätt. En 20-procentig hit rate genom blint gissande är fullt godtagbart för en angripare. (Sprays implementering lider av flera problem men det lämnas som en övning för läsaren.)
En annan faktor än (lite slarvigt) lösningsrymden är (lite slarvigt) problemrymden. Hur många bilder har Spray i databasen? Är det möjligt att ladda ner alla och identifiera dem en gång och sedan utnyttja kunskapen för att lösa alla framtida? Om databasen innehåller 200 bilder är det något jag skulle kunna ägna några timmar åt. Om databasen innehåller 3,4 miljoner bilder är jag inte riktigt lika sugen.
Det här knyter an i text-CAPTCHA-metoden. Standardattacken är att använda OCR-program (Optical Character Recognition) för att tolka bilden som text. Om de textsträngar som testet använder är riktiga ord från t ex engelska så minskar antalet möjliga gissningar radikalt. Om OCR-programmet analyserar en bild, hittar en text och tolkar den som BRNANA men samtidigt meddelar att den är osäker på den andra bokstaven är det förstås ett enkelt steg att kontrollera med en ordlista innan gissning. Sannolikt kommer det att visa sig att BANANA har det kortaste avståndet till BRNANA.
Ytterligare en uppenbar svaghet är algoritmer som inte utnyttjar slumptal. Om de deformationer som används för att förvränga texten alltid är samma har angripare möjlighet att hitta andra deformationer som inverterar effekten. (Det här beror förstås på att data inte förloras vid vissa deformationer, något som somliga har fått lära sig den hårda vägen.)
En mindre uppenbar svaghet i text-CAPTCHA-bilder är när enskilda bokstäver är enkla att separera från varandra. Jämför t ex Googles nuvarande CAPTCHA med en av de tidigaste exemplen; EZ-Gimpy nedan. Om bokstäverna kan anlyseras var för sig förenklas attacker rejält.

Redan under CAPTCHAs barndom fruktade man att människor skulle utnyttjas för att lösa testerna. En farhåga man hade var att porrsidor skulle sättas upp där besökare fick lösa en CAPTCHA varje gång de ville se ett gäng bilder. De test som besökarna löste genererades inte av porrservern utan skulle då tas från Hotmails användarregistrering så att porrsurfare, ovetandes, registrerade mailkonton. De goda nyheterna är att det här aldrig blev ett riktigt problem, åtminstone inte vad man vet. De dåliga nyheterna är istället att CAPTCHA-knäckare rekryterades i låglöneländer. Det finns tyvärr inte så mycket information om hur utbredd metoden är.
Förutom detta finns det förstås flera exempel på program avsedda för att knäcka CAPTCHA-tester.
Andra problem
Det är inte det här inläggets fokus men det är viktigt att påpeka; CAPTCHA-tester må vara svåra för dagens datorer att lösa men de är också svåra för en ansenlig del människor. En arbetsgrupp på W3C släppte en rapport på ämnet för fem år sedan; Inaccessibility of CAPTCHA:
A common method of limiting access to services made available over the Web is visual verification of a bitmapped image. This presents a major problem to users who are blind, have low vision, or have a learning disability such as dyslexia. This document examines a number of potential solutions that allow systems to test for human users while preserving access by users with disabilities.
Rekommendationer
Precis som med kryptering så ska man inte göra som Martin Timell; själv. Lägg istället krut på en känd CAPTCHA. Jag rekommenderar vanligtvis reCAPTCHA (som är gratis). Huvudsaken är att eventuellt lyckade attacker hanteras relativt snabbt. Det hände till exempel med just reCAPTCHA i december. När en sådan utbredd CAPTCHA knäcks är det större chans att det upptäcks, rapporteras och hanteras.
Generellt är det ganska svårt att ge riktlinjer för hur en stark CAPTCHA ser ut. Olika deformationer och algoritmer kan tillsammans ha oförutsedda effekter. Eftersom konceptet CAPTCHA är fött på universitet finns det gott om utrymme för en akademisk syn...

Trots detta kan några riktlinjer vara:
- Det ska vara svårt att separera enskilda tecken.
- Det ska finnas slumpmässighet på både enskilda tecken och hela ordet.
- Nyanser av färger (även gråskalor) är lätta att ta bort.
- Strikt horisontella och vertikala streck är lätta att ta bort.
- Streck som är tunnare än texten är de lätta att ta bort.
--
Stefan Pettersson
Gartner är på vår sida i bankfrågan
På TechWorld finns nu artikeln Hackare hotar överlista bankerna där det talas om Gartner-rapporten om tvåfaktorsautentisering från i december förra året; Where Strong Authentication Fails and What You Can Do About It. I korthet handlar det om att bankernas tvåfaktors inte kan stoppa en angripare som har kontroll över webbläsaren (populärt: Man In The Browser).
Det här stämmer alltså och är vad jag skrev om här och här och CJ gav rekommendationer om här.
Sammanfattningen av rapporten lyder så här [jag har lagt till numreringen]:
Fraudsters have definitely proved that strong two-factor authentication methods that communicate through user browsers can be defeated, and that the criminals can also figure out how to defeat out-of-band, telephony-based authentication and transaction verification using social-engineering techniques. While future attack types are unpredictable, one thing is very clear. Enterprises need to protect their users and accounts using a three-prong fraud prevention approach that employs (1) authentication, (2) fraud detection, and (3) out-of-band transaction verification and signing for high-risk transactions.
(1) och (2) är självklara. (3) handlar om ungefär det vi bloggat om tidigare; fokusera på transaktionen. Gartner kommer faktiskt med en viktig poäng i slutet:
[...] Further, enterprises should not deluge users with transaction verification requests, and should keep them simple and confined to high-risk transactions, so that users are sure to pay detailed attention to them.
--
Stefan Pettersson
Det här stämmer alltså och är vad jag skrev om här och här och CJ gav rekommendationer om här.
Sammanfattningen av rapporten lyder så här [jag har lagt till numreringen]:
Fraudsters have definitely proved that strong two-factor authentication methods that communicate through user browsers can be defeated, and that the criminals can also figure out how to defeat out-of-band, telephony-based authentication and transaction verification using social-engineering techniques. While future attack types are unpredictable, one thing is very clear. Enterprises need to protect their users and accounts using a three-prong fraud prevention approach that employs (1) authentication, (2) fraud detection, and (3) out-of-band transaction verification and signing for high-risk transactions.
(1) och (2) är självklara. (3) handlar om ungefär det vi bloggat om tidigare; fokusera på transaktionen. Gartner kommer faktiskt med en viktig poäng i slutet:
[...] Further, enterprises should not deluge users with transaction verification requests, and should keep them simple and confined to high-risk transactions, so that users are sure to pay detailed attention to them.
--
Stefan Pettersson
Debatt: Säkerhet är inte alltid i vägen
Jag fick en debattartikel publicerad på TechWorld nyss; Säkerhet är inte alltid i vägen.
Donald Norman, huvudsakligen känd för boken The Design of Everyday Things, skrev för en tid sedan en artikel om säkerhet; When Security Gets in the Way. En väldigt intressant text som jag kopplar till problemet säkerhetsfunktionalitet och säkerhetskvalitet som ligger svenska OWASP-ledaren John Wilander nära hjärtat. Ursäkta den skamlösa referensen till DN-artikeln. ;-)
--
Stefan Pettersson

Donald Norman, huvudsakligen känd för boken The Design of Everyday Things, skrev för en tid sedan en artikel om säkerhet; When Security Gets in the Way. En väldigt intressant text som jag kopplar till problemet säkerhetsfunktionalitet och säkerhetskvalitet som ligger svenska OWASP-ledaren John Wilander nära hjärtat. Ursäkta den skamlösa referensen till DN-artikeln. ;-)
--
Stefan Pettersson
Att planka fester
En artikel av Sebastian Suarez-Golborne för DN På stan, helt i min smak; Arbetsmetoder: så gör plankarna för att ta sig in.
Ful-osa och stämpelgnugg är klara favoriter, båda kan jämföras med replay-attacker. Om jag hade en egen klubb skulle alla stämplar ha en nonce.
--
Stefan Pettersson
Ful-osa och stämpelgnugg är klara favoriter, båda kan jämföras med replay-attacker. Om jag hade en egen klubb skulle alla stämplar ha en nonce.
--
Stefan Pettersson
Google, Adobe, Kina och trojaner
I tisdags gick Google ut med att de har utsatts för flera hackerattacker under förra året. Under eftermiddagen igår och under dagen idag verkar det kablas ut i större utsträckning.
In mid-December, we detected a highly sophisticated and targeted attack on our corporate infrastructure originating from China that resulted in the theft of intellectual property from Google. However, it soon became clear that what at first appeared to be solely a security incident--albeit a significant one--was something quite different.
Den obekräftade teorin är att Kinesiska staten är ute efter kinesiska människorättsaktivister. Låter det som en Tom Clancy-roman? Var inte så säker, tidigare fynd har pekat åt samma håll. För lite mindre än ett år sedan slåpptes två rapporter (Snooping Dragon och Ghostnet) som beskrev attacker mot Dalai Lama och Tibetrörelsen. Mycket pekade på att Kinesiska staten låg bakom. Se t ex kommentarerna till Ross Andersons blogginlägg från släppet av ena rapporten.
Attackerna har flera saker gemensamt, bland annat riktade attacker med trojaniserade PDF-filer. Vi nämnde ju häromveckan att en ny 0day för Adobe Reader kom ut innan julhelgerna.
Ironiskt nog har Adobe, hjärnorna bakom nämnd sårbarhet, gått ut och berättat att de också är påverkade av intrången som Google redogjorde för.
F-Secures blogg är en bra källa av information om riktade attacker med trojaner:
Som jag brukar säga, det finns en hel del man kan göra men inget fungerar perfekt:
Uppdatering @ 2010-01-15: Ja, och kör inte heller gamla, förlegade webbläsare som IE 6 eller gamla versioner av Firefox t ex.
Uppdatering @ 10 minuter senare: SITIC håller uppenbarligen med, ett blixtmeddelande kom precis:
Sannolikheten att utnyttja säkerhetshålet i Internet Explorer 8 är mindre eftersom DEP (Data Execution Prevention) är påslaget som standard. Detta gäller även Windows Vista och Windows 7 eftersom skyddsmekanismen ASLR (Address Space Layout Randomization) används i dessa versioner av Windows.
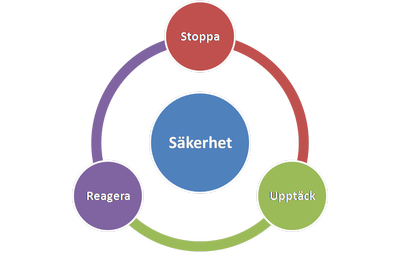
Det är svårt (omöjligt) att förhindra attacker helt. Som tur är finns det två andra delar i den stora, oformliga massan vi kallar säkerhet; vi måste UPPTÄCKA attacker och GÖRA NÅGOT åt dem. Nedan smart illustrerat med SmartArt från Microsoft Office. Vad som är svårt på riktigt är att bestämma sig för hur mycket pengar som ska läggas på varje cirkel. Vi ska återkomma till det här och att mäta säkerhet.
Stefan Pettersson
In mid-December, we detected a highly sophisticated and targeted attack on our corporate infrastructure originating from China that resulted in the theft of intellectual property from Google. However, it soon became clear that what at first appeared to be solely a security incident--albeit a significant one--was something quite different.
Den obekräftade teorin är att Kinesiska staten är ute efter kinesiska människorättsaktivister. Låter det som en Tom Clancy-roman? Var inte så säker, tidigare fynd har pekat åt samma håll. För lite mindre än ett år sedan slåpptes två rapporter (Snooping Dragon och Ghostnet) som beskrev attacker mot Dalai Lama och Tibetrörelsen. Mycket pekade på att Kinesiska staten låg bakom. Se t ex kommentarerna till Ross Andersons blogginlägg från släppet av ena rapporten.
Attackerna har flera saker gemensamt, bland annat riktade attacker med trojaniserade PDF-filer. Vi nämnde ju häromveckan att en ny 0day för Adobe Reader kom ut innan julhelgerna.
Ironiskt nog har Adobe, hjärnorna bakom nämnd sårbarhet, gått ut och berättat att de också är påverkade av intrången som Google redogjorde för.
F-Secures blogg är en bra källa av information om riktade attacker med trojaner:
- PDF Most Common File Type in Targeted Attacks (maj 2009)
- Creating Malicous PDF Files (juni 2008)
- DHS PDF (juni 2008)
- Spying via XLS files (april 2009)
Som jag brukar säga, det finns en hel del man kan göra men inget fungerar perfekt:
- Kör inte som administratör.
- Använd moderna operativsystem som Windows Vista/7.
- Uppdatera tredjepartsprogramvara.
- Använd antivirus på mail-gateways.
- Var misstänktsam mot bifogade filer.
- ...
Uppdatering @ 2010-01-15: Ja, och kör inte heller gamla, förlegade webbläsare som IE 6 eller gamla versioner av Firefox t ex.
Uppdatering @ 10 minuter senare: SITIC håller uppenbarligen med, ett blixtmeddelande kom precis:
Sannolikheten att utnyttja säkerhetshålet i Internet Explorer 8 är mindre eftersom DEP (Data Execution Prevention) är påslaget som standard. Detta gäller även Windows Vista och Windows 7 eftersom skyddsmekanismen ASLR (Address Space Layout Randomization) används i dessa versioner av Windows.
Det är svårt (omöjligt) att förhindra attacker helt. Som tur är finns det två andra delar i den stora, oformliga massan vi kallar säkerhet; vi måste UPPTÄCKA attacker och GÖRA NÅGOT åt dem. Nedan smart illustrerat med SmartArt från Microsoft Office. Vad som är svårt på riktigt är att bestämma sig för hur mycket pengar som ska läggas på varje cirkel. Vi ska återkomma till det här och att mäta säkerhet.
Stefan Pettersson
Jul och nyår
Under jul- och nyårshelgerna vill man förstås ha det lugnt och stilla. Även så i nätverket. Ett gammalt djungelordspråk säger dock att "hackers arbetar på semestern". Några exempel:
Nyår 2005-2006 släpptes ett riktigt hårigt exploit för Windows; "WMF-exploitet" (MS06-001).
Nyår 2006-2007 knäcktes AACS (Advanced Access Content System) DRM-skyddet i HD-DVD.
Nyår 2007-2008 rullades ett omfattande intrång hos Aftonbladet upp.
Nyår 2008-2009 kom "the Curse of Silence", ett exploit som levererades över SMS (blev ingen hit direkt).
Vad har hänt den här gången då?
Gävlebocken
En nämnvärd händelse är ju bland annat den, något risktagande, Gävlebockens öde. För att citera Bocken själv:
Fruktansvärd natt! Sov sött under mitt vackra snötäcke när det plötsligt blev otäckt varmt. Det var eld!!! Vid tretiden lyckades någon bränna ned mig och förstöra den fantastiska julstämningen i Gävle. [...]
Gävlebockens webbkameror utsattes för en kraftig trafikökning från kl. 14 den 22 december fram till 03-tiden i natt. Detta innebar att webbkamerorna uppdaterades betydligt långsammare och det finns inga bilder från antändningen. Normalt sett uppdateras kamerabilderna var 3-4 sekund, medan det i natt kunde ta 10 minuter för bilderna att uppdaterats. Vi misstänker att det kan röra sig om en överbelastningsattack med syfte att göra webbkamerorna långsammare under själva attentatet.
Intressant i sammanhanget är att Gävle kommun inte får spara bilderna eftersom webbkamerorna inte räknas som övervakningskameror (rätt mig om jag har fel). De utgår från att få screenshots på relevanta kamerabilder av allmänheten när det behövs. Om inte allmänheten kan se förövarna så kan inte kommunen se dem heller. Smarta mordbrännare.
Enorma mängder lösenord på vift
En annan stor nyhet är att RockYou.com (en stödtjänst för MySpace, Facebook o s v) har gjort jordens blunder och åkt dit på tidernas lösenordsläcka. Sammanfattningsvis: (1) RockYou har extremt många användare, (2) de lagrar användarnas lösenord i klartext, (3) webbapplikationen har en SQL injection-sårbarhet och (4) en hackertyp utnyttjar hålet för att slussa ut 32 miljoner användarnamn och lösenord. TechCrunch har en lite utförligare sammanfattning.
En (den enda?) trevlig bieffekt är att 32 miljoner lösenord från en väldigt varierad användarbas är ett utmärkt underlag för lösenordsstatistik. Både "123456", "12345", "123456789", "1234567" och "12345678" finns bland de tio vanligaste lösenorden. De två förstnämnda står tillsammans för mer än en procent av alla lösenord.
0day i Adobe Reader och Acrobat
Redan den 15:e december gick Adobe ut med information där man bekräftade existensen av en 0day-sårbarhet som utnyttjades "in the wild". Trots det valde man att inte göra någon särskild satsning att patcha det här utanför sitt planerade släpp, utan istället lever vi nu fortfarande med sårbara PDF-läsare runt ikring oss. Inte förrän den 12:e januari kommer en fix att släppas. Enligt Adobes "director of security and privacy" skulle det nämligen hur som helst ta 2-3 veckor att komma med en fix, och då låg Adobe redan så nära det planerade släppet den 12:e att Adobe ansåg deras användare lika gärna kunde vänta.
Ett mindre klokt beslut kan tyckas, åtminstone när man står vid sidan om och ser på. Redan dagen efter Adobes bulletin släppte H D Moore en modul till metasploit som utnyttjade sårbarheten. Och naturligtivis haglar rapporterna om utnyttjande både vad gäller riktade angrepp samt mindre riktade (30.000+).
0day i MySQL
Avslutningsvis verkar det som att en sårbarhet har upptäckts i MySQL, "lyckligtvis" återfinns den än så länge i VulnDisco-packet för exploitverktyget CANVAS istället för "in the wild". Det blir det förmodligen ändring på snart...
Välkommen till ett nytt år!
--
Stefan & CJ
Nyår 2005-2006 släpptes ett riktigt hårigt exploit för Windows; "WMF-exploitet" (MS06-001).
Nyår 2006-2007 knäcktes AACS (Advanced Access Content System) DRM-skyddet i HD-DVD.
Nyår 2007-2008 rullades ett omfattande intrång hos Aftonbladet upp.
Nyår 2008-2009 kom "the Curse of Silence", ett exploit som levererades över SMS (blev ingen hit direkt).
Vad har hänt den här gången då?
Gävlebocken
En nämnvärd händelse är ju bland annat den, något risktagande, Gävlebockens öde. För att citera Bocken själv:
Fruktansvärd natt! Sov sött under mitt vackra snötäcke när det plötsligt blev otäckt varmt. Det var eld!!! Vid tretiden lyckades någon bränna ned mig och förstöra den fantastiska julstämningen i Gävle. [...]
Gävlebockens webbkameror utsattes för en kraftig trafikökning från kl. 14 den 22 december fram till 03-tiden i natt. Detta innebar att webbkamerorna uppdaterades betydligt långsammare och det finns inga bilder från antändningen. Normalt sett uppdateras kamerabilderna var 3-4 sekund, medan det i natt kunde ta 10 minuter för bilderna att uppdaterats. Vi misstänker att det kan röra sig om en överbelastningsattack med syfte att göra webbkamerorna långsammare under själva attentatet.

Intressant i sammanhanget är att Gävle kommun inte får spara bilderna eftersom webbkamerorna inte räknas som övervakningskameror (rätt mig om jag har fel). De utgår från att få screenshots på relevanta kamerabilder av allmänheten när det behövs. Om inte allmänheten kan se förövarna så kan inte kommunen se dem heller. Smarta mordbrännare.
Enorma mängder lösenord på vift
En annan stor nyhet är att RockYou.com (en stödtjänst för MySpace, Facebook o s v) har gjort jordens blunder och åkt dit på tidernas lösenordsläcka. Sammanfattningsvis: (1) RockYou har extremt många användare, (2) de lagrar användarnas lösenord i klartext, (3) webbapplikationen har en SQL injection-sårbarhet och (4) en hackertyp utnyttjar hålet för att slussa ut 32 miljoner användarnamn och lösenord. TechCrunch har en lite utförligare sammanfattning.
En (den enda?) trevlig bieffekt är att 32 miljoner lösenord från en väldigt varierad användarbas är ett utmärkt underlag för lösenordsstatistik. Både "123456", "12345", "123456789", "1234567" och "12345678" finns bland de tio vanligaste lösenorden. De två förstnämnda står tillsammans för mer än en procent av alla lösenord.
0day i Adobe Reader och Acrobat
Redan den 15:e december gick Adobe ut med information där man bekräftade existensen av en 0day-sårbarhet som utnyttjades "in the wild". Trots det valde man att inte göra någon särskild satsning att patcha det här utanför sitt planerade släpp, utan istället lever vi nu fortfarande med sårbara PDF-läsare runt ikring oss. Inte förrän den 12:e januari kommer en fix att släppas. Enligt Adobes "director of security and privacy" skulle det nämligen hur som helst ta 2-3 veckor att komma med en fix, och då låg Adobe redan så nära det planerade släppet den 12:e att Adobe ansåg deras användare lika gärna kunde vänta.
Ett mindre klokt beslut kan tyckas, åtminstone när man står vid sidan om och ser på. Redan dagen efter Adobes bulletin släppte H D Moore en modul till metasploit som utnyttjade sårbarheten. Och naturligtivis haglar rapporterna om utnyttjande både vad gäller riktade angrepp samt mindre riktade (30.000+).
0day i MySQL
Avslutningsvis verkar det som att en sårbarhet har upptäckts i MySQL, "lyckligtvis" återfinns den än så länge i VulnDisco-packet för exploitverktyget CANVAS istället för "in the wild". Det blir det förmodligen ändring på snart...
Välkommen till ett nytt år!
--
Stefan & CJ
